Als kleine Ergänzung zum Beitrag Sprachausgabe – Unser Haus kann sprechen der sehr auf die Hardware bezogen war, gibt es jetzt auf Wunsch ein HowTo nur für das Linux Text-to-Speech Gateway. Darin enthalten ist wie man das Skript unter Linux (Raspian) einrichtet und wie die Ansteuerung mit dem Loxone Miniserver und der direkte Aufruf über Webbrowser funktioniert.
Das Linux Text-to-Speech Gateway
Wie bereits im Beitrag Sprachausgabe – Unser Haus kann sprechen basiert dieses HowTo auf einem Raspberry Pi. Da seit dem Beitrag etwas Zeit vergangen ist habe ich das ganze nochmal komplett neu auf Basis von dem Raspbian Whezzy Image 2015-05-05 aufgesetzt (es sollte aber auch mit älteren Images funktionieren) und die Schritte dokumentiert. Für das Projekt wird weiterhin die inoffizielle “Google Speech API” verwendet. Es kann natürlich sein, dass Google irgendwann mal einen Riegel davor schiebt. Weiterhin bleibt aber die Limitierung bei 100 Zeichen!
Die Vorbereitung
Ein wenig Linux KnowHow setze ich einfach mal voraus, werde aber auf alle Punkte die wichtig sind eingehen.
Benötigt werden erstmal verschiedene Linux Pakete wie der Apache Webserver mit PHP5 und mpg321 zu Wiedergabe der MP3s.
sudo apt-get install apache2 php5 mpg321
Den Apache User www-data zur Gruppe audio hinzufügen damit er die Soundkarte nutzen darf. Danach muss der Rasperry Pi neu gestartet werden.
sudo usermod -G audio www-data sudo reboot
Der Raspberry Pi nutzt für die Soundausgabe automatisch den HDMI Ausgang wenn dieser angeschlossen ist. Wenn man den Analogausgang fest einstellen möchte, kann man das mit folgenden Befehl tun amixer cset numid=3 N wobei N für 0=auto, 1=analog, 2=hdmi steht.
amixer cset numid=3 1
Verzeichnis unter /var/www erstellen (in meinem Beispiel tts für Text to Speech) und Berechtigungen setzen damit per WinSCP später das Skript erstellt werden kann.
sudo mkdir /var/www/tts sudo chown pi:www-data /var/www/tts
Für das Caching wird noch ein Ordner tmp benötigt.
sudo mkdir /var/www/tts/tmp sudo chown pi:www-data /var/www/tts/tmp sudo chmod 775 /var/www/tts/tmp -R
Über den folgenden Befehl kann die Lautstärke auf zt. B. 95% angepasst werden. Diese ist ohne Anpassung sehr leise eingestellt.
amixer set PCM -- 95%
Falls ihr im Apache Error-Log die Fehlermeldung “Unknown PCM cards.pcm.front” erhaltet, müsst ihr in der /usr/share/alsa/alsa.conf ungefähr in Zeile 132 den Eintrag “pcm.front cards.pcm.front” in “pcm.front cards.pcm.default” ändern.
# redirect to load-on-demand extended pcm definitions pcm.cards cards.pcm pcm.default cards.pcm.default pcm.sysdefault cards.pcm.default pcm.front cards.pcm.default // OLD VALUE ==> pcm.front cards.pcm.front pcm.rear cards.pcm.rear pcm.center_lfe cards.pcm.center_lfe
Das PHP-Skript
Den groben Ablauf habe ich mit einem kleinen Ablaufdiagramm dargestellt.
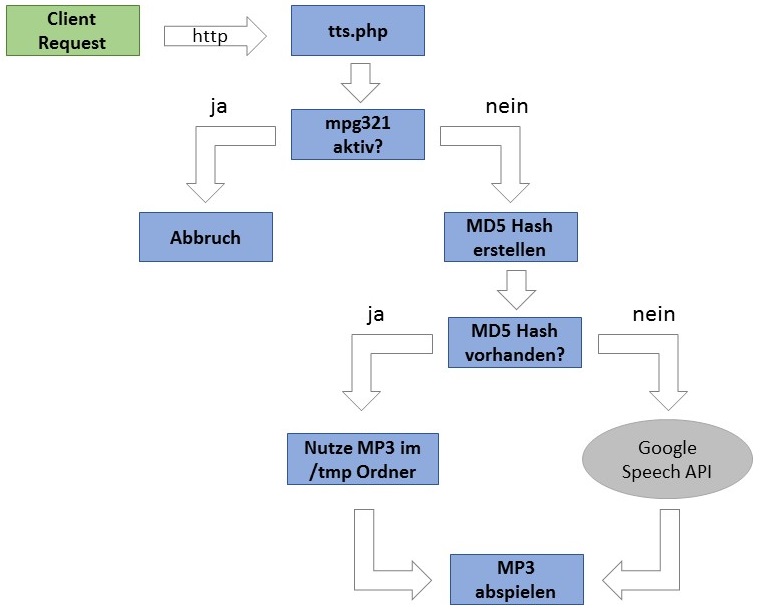
Um das Skript auf den Raspberry Pi zu bekommen verbindet man sich am besten per WinSCP und erstellt im Ordner /var/www/tts eine Datei tts.php und fügt folgende Zeilen hinzu.
<?php
// Variablen definieren
$key = "<YOUR-API-KEY-HERE>"; // Einfach auf VoiceRSS.org registrieren
$q = "44khz_16bit_stereo"; // Andere Einstellungen siehe VoiceRSS Doku
$gain = ($_GET["gain"]);
$lang = ($_GET["lang"]);
if ($gain == "")
{
$gain = "100";
}
if ($lang == "")
{
$lang = "de-de"; // Andere Einstellungen siehe VoiceRSS Doku (en-us / en-gb)
}
// Prüfen ob noch ein Prozess läuft
$pids = shell_exec("ps aux | grep -i 'mpg321' | grep -v grep");
if(empty($pids))
{
// Text anpassen
$words = urlencode($_GET['text']);
echo "Text to Speech Input: <b>" . $words . "</b><br>";
// Parameter VoiceRSS
$inlay = "key=$key&hl=$lang&src=$words&f=$q"; // Variablen Key, Sprache, Text und Qualität definieren
echo "Parameter VoiceRSS: <b>" . $inlay . "</b><br>";
// Name der MP3 als MD5 Hash
$fileo = md5($words);
$fileolang = "$fileo-$lang";
// Speicherort der MP3 Datei
$file = "./tmp/" . $fileolang . ".mp3";
echo "Open File: <a href=" . $file . ">Download</a>";
// Prüfen ob die MP3 Datei bereits vorhanden ist
if (!file_exists($file))
{
$mp3 = file_get_contents('http://api.voicerss.org/?' . $inlay); // HTTPS ist auch möglich
file_put_contents($file, $mp3);
}
shell_exec("mpg321 -g $gain ./tmp/$fileolang.mp3 &");
}
else
{
echo "Fehler!";
}
Webbrowser
Die einfachste Variante ist natürlich der direkte Aufruf der Linux Text-to-Speech Schnittstelle über einen Webbrowser. Im Grunde genommen macht der Loxone Miniserver ja nichts anderes. Auf diesem Weg kann man das Linux Text-to-Speech Gateway auch sehr einfach für andere Projekte nutzen.
Um einen Text bei 100% Lautstärke abzuspielen genügt.
http://<IP Adresse Raspberry Pi>/tts/tts.php?text=Willkommen Zuhause
Will man die Lautstärke anpassen wird zusätzlich die Variable gain benötigt. Man kann auch über 100% einstellen, dies kann aber zu Verzerrungen führen.
http://<IP Adresse Raspberry Pi>/tts/tts.php?gain=50&text=Willkommen Zuhause
Die Sprache (Standard Deutsch) lässt sich auch leicht ändern.
http://<IP Adresse Raspberry Pi>/tts/tts.php?lang=en&text=Welcome Home
Loxone Miniserver
Als erstes legt man in der Loxone Config einen virtuellen Ausgang an. Hier muss die IP-Adresse des Raspberry Pi eintragen und Verbindung nach Senden schließen angehakt werden.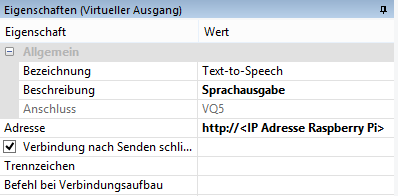
Für jeden Text muss jetzt ein virtueller Ausgang Befehl angelegt werden. Dazu muss, wie bei Webbrowser beschrieben, unter Befehl EIN mindestens so etwas wie /tts/tts.php?text=Hier steht der Text eingetragen werden.
Update 2015-08-21
Da ich immer noch nicht dazu gekommen bin das TTS Gateway selber zu nutzen, ist mir gar nicht aufgefallen das Google leider seine TTS API umgestellt und eine Captcha Abfrage eingebaut hat.
$inlay = "$lang&q=$words&ie=UTF-8&total=1&idx=0&client=t";
Über der Zeile $mp3 = file_get_contents(… auch noch folgendes eintragen damit ein gültiger User Agent (Brwoser) übermittelt wird.
ini_set("user_agent"," Mozilla/5.0 (Windows; U; MSIE 7.0; Windows NT 6.0; en-US)");
Durch eine Erweiterung der $inlay Variable und Übermittlung vom User Agent lässt sich scheinbar die Captcha Abfrage erstmal umgehen. Wie lange kann ich natürlich nicht sagen.
Update 2015-12-15
Da Google wieder aufgerüstet hat und keine Besserung in Sicht ist, habe ich mal den Kommentar von Oliver aufgegriffen und den Anbieter VoiceRSS.org als Standard Anbieter in das Skript eingebaut. Ich habe die für die Google API relevanten Teile auskommentiert und entsprechende Kommentare eingefügt. Es ändert sich, abgesehen von den optional verwendbaren Kürzeln für andere Sprachen, nur das Skript und nicht der HTTP-Befehl!
Update 2017-03-31
Zur Übersichtlichkeit habe ich die Google Kommentare aus dem PHP-Skript entfernt und noch ein paar Ausgaben hinzugefügt um das Troubleshooting zu erleichtern. Zudem habe ich einen Hinweis für die Anpassung der Lautstärke hinzugefügt, eine Anpassung in der alsa.conf falls die interne analoge Soundkarte genutzt werden soll und den Aufrufparameter für mpg321 angepasst (-q für Quiet mode entfernt) um die Fehlermeldung “tcgetattr(): Inappropriate ioctl for device” im Apache2 Error-Log zu unterbinden. Zur Info: Das Skript funktioniert auch noch unter Raspian Jessie Lite vom 2017-02-16.
Hi,
super! Habe ich schon fast 2 Tage lang probiert! Aber der Hinweis mit www-data der audio group hinzufügen hat mir gefehlt..
Danke!
Dieter
Hallo Stefan!
Tolles Projekt, hab versucht es nachzubauen, nur leider wird mir das MP3 nicht geholt!
Der Grund dafür ist, meines Achtens, das Google bei der Abfrage einen Captcha eingebaut hat, und der Raspberry da nicht drüberkommt!
Danke Michael
PS: Gibt es eigentlich einen andere TTS-Machine?
Hallo,
funktioniert das Script noch?
Habe es gerade getestet, ich bekommt von Google nur eine Fehlermeldung zurück… 302
Wenn ich über den Browser die URL eingebe will er ein Captcha ausgefüllt.
Bei dir nicht so?
Gruß
Dieter
Hallo zusammen,
ich habe erstmal eine Lösung gefunden das Captcha Problem zu umgehen. Siehe dazu den aktualisierten Beitrag.
Viele Grüße
Stefan
Hallo Stefan,
Anscheinend hat Google den TTS API wieder umgestellt. Im Moment sieht die Lage so aus, dass wenn zu viele Anfragen in einer kurzen Zeit gesendet werden, die Anfragen blockiert werden mit folgender Rückmeldung:
********************************************************************************************
Unsere Systeme haben ungewöhnlichen Datenverkehr aus Ihrem Computernetzwerk festgestellt. Bitte versuchen Sie es später erneut.Warum?
IP-Adresse: ***.***.***.***
Uhrzeit: 2015-11-19T15:56:51Z
URL: http://www.google.com/
********************************************************************************************
Gibt es schon eine Möglichkeit dies zu umgehen? Ein großes Problem im Script besteht darin, dass die MP3 Files trotzdem erstellt werden mit 0KB, auch wenn die Translation nicht funktioniert bzw. blockiert wurde.
Gruss Adrian
Hallo Adrian,
die TTS API von Google macht mir auch Probleme. Ich bin schon seit längerem immer mal wieder auf der Suche nach einer Alternative, habe aber bisher noch nicht die richtige Lösung gefunden.
Im Script könnte man die Größe mit filesize bestimmen und mit unlink löschen wenn diese 0 KB groß ist.
Viele Grüße
Stefan
Hi Stefan,
vielen Dank für deine Arbeit, dein Script läuft wunderbar. Nachdem Google TTS ja nicht mehr verfügbar ist habe ich mich mal nach anderen Online/Offline Engines umgeschaut und verwende mittlerweile voicerss.org.
Die Qualität der Sprachausgabe ist wirklich gut und die API ähnlich wie Google. Die Restriktion ist 350 Calls per day und die Empfangsdatei darf max. 100KB sein, was bei mir aber noch nicht eintraf.
Ich verwende das ganze in Verbindung mit Sonos und es läuft stabil und einwandfrei.
Vielleicht hilft Dir der Tip ja.
Gruß Oliver
Hallo Oliver,
vielen Dank für die Info! Ich habe das Skript auf die Nutzung von Voice RSS umgebaut und bin auch sehr zufrieden mit der Qualität. Es sind sogar mehr als 100 Zeichen möglich. Die 350 Calls pro Tag sollten mit dem Cache für viele Zwecke ausreichend sein. Ich werde das Skript gleich mal anpassen und ein paar Zeilen dazu schreiben.
Viele Grüße
Stefan
He Stefan,
bekomme das Script bei mir nicht zum laufen… Erhalte immer Fehler 500.
Habe mir den Code mal angesehen, der Doppelslash wird bei mir als Kommentar interpretiert.
Wie hast Du das gelöst?
Grüße
Mike
Hallo Mike,
bin gerade unterwegs, bitte prüfe doch mal mit folgendem Befehl was im Apache Error Log steht. Das Skript habe ich so getestet und kann auch gerade im Skript keinen Formatierungsfehler sehen?!
tail -f /var/log/apache2/error.log
Viele Grüße
Stefan
Hallo,
Super Tutorial!
Kann es sein, dass die Dateien und Ordner nun in /var/www/html/ rein müssen, oder mache ich da was falsch?
Zumindest läuft das script bei mir nur dann, wenn ich die Daten entsprechend in diesen Ordne schiebe.
Der direkte Aufruf des scripts über den Browser klappt so einwandfrei, aber per Loxone Befehl will es einfach nicht klappen.
Eine Idee wie ich den Fehler finden kann?
Hallo Tobi,
du nutzt sicherlich ein anderes Image als ich oder?! Je nach Distribution/Package kann es ein anderer Pfad sein, bei Raspian Jessie müsste es z. B. /var/www/html sein. Aber wenn es funktioniert ist alles gut! 🙂
Schau mal ins Apache Log ob da was ankommt. Am besten mit tail -f /var/log/apache2/access.log das Log aufmachen und zeitgleich einen Befehl von dem Loxone Miniserver senden. Wenn im Log nichts ankommt, kann das Problem eigentlich nur auf der Seite der Loxone liegen. Den Raspberry Pi kann man ja schon ausschließen da über den Browser die Sprachausgabe klappt.
Viele Grüße und guten Rutsch
Stefan
Super, der Apache Log hat den Fehler sofort aufgezeigt.
Der Loxone Ausgangsbefehl hatte ein Leerzeichen zu Beginn. Nachdem das Leerzeichen gelöscht war, lief es sofort einwandfrei.
Dieses Leerzeichen hätte ohne den Apache Log wahrscheinlich nie gefunden.
Vielen Dank und auch dir einen guten Rutsch!
Hallo,
Vielen Dank für deinen Beitrag.
Ich habe aber noch ein Problem: das zusammen bauen von “inlay” schlägt fehl.
Ich habe alle Google API Kommentare gelöscht.
Er meckert aber dass entweder eine Klammer, Semikolon fehlt. Ich kann aber keine Stelle finden an der etwas fehlen sollte bzw. Etwas falsch ist.
Hallo Christian,
ich habe den Beitrag ein wenig aktualisiert. Das PHP-Skript aus dem Beitrag habe ich so selbst in Verwendung. Probiere es doch bitte noch einmal und achte ggf. auf die Formatierung.
Viele Grüße
Stefan
Nachdem ich dein kleines php-script im täglichen Gebrauch habe, durch das Cachen jedoch nicht bemerkt habe, dass voicerss ihre API leicht abgewandelt haben, hier ein kleiner Hinweis für alle, die auch Probleme bzw. nur Rauschen bei neuen Abfragen haben:
Voicerss schickt standardmäßig die Dateien nun als WAV, nicht als MP3, daher muss man bei der Anfrage explizit MP3 als Ausgabeformat auswählen. Die Änderung dazu ist denkbar simpel – einfach die Zeile
$inlay = “key=$key&hl=$lang&src=$words&f=$q”;
durch
$inlay = “key=$key&hl=$lang&src=$words&f=$q&c=MP3”;
ersetzen.
Danke für das super Script und Tutorial!
Hallo,
danke f. das tolle script, verwende es schon seit über einem Jahr um Sprachmeldungen von der Loxone über den Raspberry Pi auf einen Echo Dot auszugeben, den ich als Bluetooth Lautsprecher mit dem Raspberry verbunden habe.
Seit einigen Tagen habe ich aber das Problem, dass zusätzlich zur Sprachausgabe auch der Echo Dot folgendes sagt: “Musik wird von Loxone abgespielt.”
Loxone ist der Netzwerkname des Raspberry.
Nur wenn alle paar Minuten ein Sprachausgabe erfolgt, wird diese Ansage nicht ausgegeben.
Habe bereits den Echo Dot auf “Kurzantwort” gestellt und alle “Anfragetöne” deaktiviert.
Habt ihr eine Lösung ? Freundliche Grüße, Andreas